どうもどうも。
前にTwitterに投げたちょっとのスクリプトを少しだけ整理しました。
こういう、2分で書けたのに将来的に数十分もお得で、
しかもMPが温存できる類のものはいいですねえ。捨てるに惜しい書き捨て系。
売り物にはならないやつ。
普段は「とりあえずは要件通り動いたからまあいっか」なんですが
今回「もうちょっとなんとかならないものなのかとも思う」
という、自分にしてはけっこう珍しい引っ掛かりを感じたので、
誰かが教えてくださるのをここで待ちます。アンコウの構え。
コード全体はこちら。今回ダウンロードありません。
あそびかた
論文なんかの、文末や巻末にある文献で、
その文献の参考にしたページ範囲の表記ってのがありまして。
「pp.1234-1256」みたいな箇所ですね。
これがたまに方言なのか、変動していない桁を省略して
「pp. 1234-56」なんて書き方があるようで、ここによく桁数を一致させる旨の赤字が入ります。
たいして面倒ではないんだけど、ものすごく自動化の香りがしますね。
まあ、当該テキストを選択して実行すると、

いい感じになるわけです。
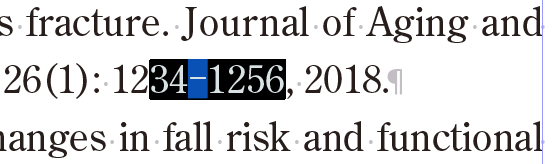
解説のつもり
ではコードひもとき。
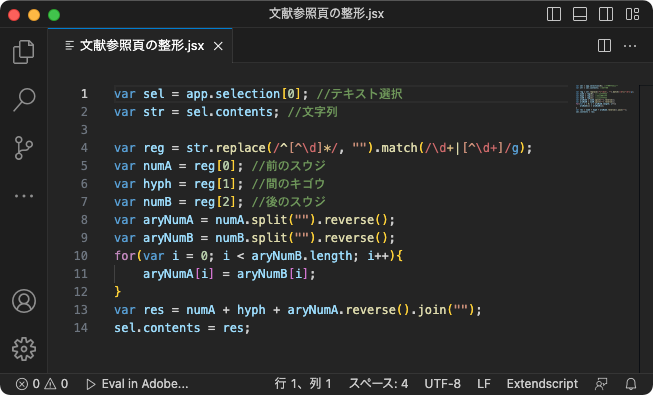
var sel = app.selection[0];
ここの説明は不要かもですが、選択オブジェクトをひとつ変数に入れています。
雑に書いたスクリプトなので、何も選択されていないとのっけからエラーで止まります。
var str = sel.contents;
選択されたのがテキストだと決め打ちした上で、その文字列を変数に入れています。
雑に書いたスクリプトなので、テキスト以外が選択されていると余裕でエラーが出ます。
var reg = str.match(/\d+|[^\d+]/g);
var numA = reg[0]; //前のスウジ
var hyph = reg[1]; //間のキゴウ
var numB = reg[2]; //後のスウジ
ここは最初に2分間で書いたものが雑すぎたので少し直しました。
「数字のひとかたまり、または 数字じゃないひとかたまり」をつかんで、
その結果を3種の変数に順に入れています。
ここも選択範囲内のテキストが要件に適っていなかったら余裕でエラーが出ます。
これでも雑だっていう話ですな…
var aryNumA = numA.split("").reverse();
var aryNumB = numB.split("").reverse();
変数 numA と numB を1文字ずつばらして配列化しています。
さらに後工程のために、配列の並びを逆にしています。
“ビートルズ” が “ずうとるび” になります(ならないです)。
for(var i = 0; i < aryNumB.length; i++){
aryNumA[i] = aryNumB[i];
}
今回の肝となる処理。
前の数字 aryNumA をベースにして、それよりも桁数が短い後の数字 aryNumB の数字を
桁ごとにもらっています。aryNumB にはない桁は元々の aryNumA の物が残る仕組み。
var res = numA + hyph + aryNumA.reverse().join("");
sel.contents = res;
仕上げ。前の数字と、間の記号 まではそのまま。
加工した配列 aryNumA を、配列の並びを逆にして結合。
で元の選択範囲の文字列に指定。
つまり、選択した文字列の先頭・末尾に余計な文字が入っている場合はこの瞬間に消えてなくなります。
どこまでも雑。
ズ
仕上げ部分のロジックを図にすると、こう。

aryNumAをベースに、aryNumBに存在する桁だけを入れ替える。
aryNumBに存在しない桁はaryNumAのものがそのまま残るという仕組み。
ということで
配列化するのが無駄だとか、
Bの存在する要素をAに、ではなくAだけに存在する要素をBに代入したほうがスマートだとか
そういうのはなんとなくわかるんだけど、もっとこう、
ビット演算的ななんか、なかったかなあ、と思ってやまない。
ので、誰かそっとおしえてください。
そこまで求道しないって人は現状でそのまま使ってもらって大丈夫です。動きます。
エラー回避の練習してみたい人にはちょうどいいかもしれません(すごい詭弁)。